Приведена последовательность действий, согласно которой сделан выбор метода для решения задачи о сравнении параметров распределения полученной выборки. Другими словами, описание разработанной методологии статистического анализа данных, полученных в ходе опроса 498 аптек-респондентов, а именно работников первого стола, в 25 региональных центрах Украины с развитой аптечной инфраструктурой.
Определение объема выборки
Чтобы получить достоверные результаты выборочных исследований, выборка должна быть однородной и репрезентативной. При выборке изучаемой совокупности факторов (ответы анкет), влияющих на рекомендацию определенного препарата провизором потребителю, не должно быть противоречий, изучаемая выборка должна быть репрезентативной (соответствующей) генеральной совокупности. В ходе исследования учтено общее количество фармацевтов-провизоров в Украине, составляющее более 30 тыс. человек, из которых около 20 тыс. человек — работники первого стола в областных центрах (согласно информации Государственного комитета статистики Украины (Госкомстата), 2002 г.). Для выяснения вопроса, сколько данных необходимо собрать, проведено установочное пилотное исследование. В ходе его определено необходимое количество аптек-респондентов при уровне достоверности полученных данных 95% (предельно допустимая ошибка d составила 5%).
Расчеты производили по формуле определения объема выборки при заданной абсолютной точности в оценке значений:
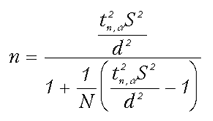 |
где N — размер генеральной совокупности; d — абсолютное значение предельно допустимой ошибки в определении значения; S2 — оценка выборочной дисперсии; tn,a — для числа степеней n и уровня значимости a. Поскольку n точно не известно, для расчетов берут приближенное значение tn,a? ~ 2.
Размер выборки сильно зависит от дисперсии, то есть от степени разброса данных — чем больше дисперсия, тем бoльшим должен быть размер выборки. Дисперсия постоянной величины равна 0. Если все результаты увеличить или уменьшить на одно и то же число, то дисперсия не изменится. Если все результаты изменить в К раз (например, с учетом коэффициента инфляции), то дисперсия изменится в К2 раз (тот факт, что в период инфляции бедные становятся беднее, а богатые — богаче, с точки зрения статистики, является всего лишь свойством дисперсии). Корень квадратный из дисперсии представляет собой среднеквадратическое отклонение S (стандартное отклонение). С учетом вышеперечисленных свойств применена формула вычисления эмпирической дисперсии:
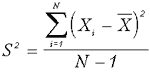 |
Для обеспечения репрезентативности выборки генеральной совокупности (общее количество фармацевтов/провизоров первого стола) в каждом из исследуемых областных центров и согласно имеющемуся соотношению количества аптек к количеству населения (потенциальных потребителей) методом случайного отбора была определена экспертная группа (стратифицированная выборка). Эта выборка составила 498 аптек-респондентов, необходимых для получения достоверных данных.
Выбор метода статистического анализа
В связи с тем что при статистическом анализе использовали дискретную шкалу измерений, в дальнейшем было сочтено целесообразным применение непараметрического критерия в оценке полученных данных. Во всех случаях при использовании непараметрических критериев допускается следующее:
-
все случайные величины взаимно независимы;
-
анализируемые выборки распределены по непрерывному распределению одного и того же вида.
В данном исследовании проверяли гипотезу о равенстве не среднего, а медианного значения. Это связано с тем, что для закона распределения, отличного от нормального (измерение в дискретных шкалах), медиана является более устойчивой и корректной оценкой положения центра распределения. Определение медианного значения всей выборки (по всем заданным вопросам) производили для определения значимости каждого фактора, исходя из полученных ответов респондентов (см. рис. 1).
Полученные обобщенные данные определения медианы с учетом дисперсии и предельно допустимой ошибки приведены в табл. 1.
Таблица 1
Определение медианы с учетом дисперсии и предельно допустимой ошибки
|
Фактор |
Медиана |
Дисперсия |
d |
d, % |
|
Ф9 |
9 |
0,310031003 |
0,0486459978 |
4,86459978 |
|
Ф13 |
9 |
0,325932593 |
0,0498779332 |
4,987793319 |
|
Ф3 |
8 |
0,353735374 |
0,0519617536 |
5,196175356 |
|
Ф12 |
8 |
0,296629663 |
0,0475830025 |
4,758300246 |
|
Ф15 |
8 |
0,273527353 |
0,0456925014 |
4,569250145 |
|
Ф1 |
7 |
0,341534153 |
0,0510577442 |
5,105774417 |
|
Ф2 |
7 |
0,333533353 |
0,0504561592 |
5,045615918 |
|
Ф5 |
7 |
0,404640464 |
0,0555749663 |
5,557496632 |
|
Ф10 |
7 |
0,277727773 |
0,0460420030 |
4,6042003 |
|
Ф11 |
7 |
0,348034803 |
0,0515413620 |
5,154136202 |
|
Ф14 |
7 |
0,335333533 |
0,0505921395 |
5,059213949 |
|
Ф4 |
6 |
0,308630863 |
0,0485360277 |
4,85360277 |
|
Ф6 |
5 |
0,371837184 |
0,0532746937 |
5,327469373 |
|
Ф7 |
5 |
0,336233623 |
0,0506599928 |
5,065999277 |
|
Ф8 |
5 |
0,367636764 |
0,0529729331 |
5,297293309 |
Определение взаимосвязи между существующими факторами
Следующий шаг в исследовании был направлен на определение взаимосвязи между всеми существующими факторами (определение корреляционной последовательности) методом ранжирования вариационного ряда и вычислением коэффициента корреляции методом Спирмена. Медиана (выборочная) — это значение, которое делит ранжированный вариационный ряд на равные по объему группы.
Вариационным рядом называют значения случайной выборки (x1, x2, …xn), имеющие функцию распределения F(x) и расположенные в порядке их возрастания: x(1) < x(2) < … < x(i) < … < x(n), где i-й член вариационного ряда x(i) называют i-той порядковой статистикой, а номер члена вариационного ряда — рангом, порядком статистики. Ранжирование — это процедура перехода от совокупности наблюдений к последовательности их рангов.
В нашем случае необходимо проверить, существует ли статистически значимая связь (зависимость) между заданными факторами, которые являются параметрами в формировании мнения работника первого стола и в дальнейшей рекомендации им потребителю того или иного препарата. Для этого имеющиеся значения переменных размещают в ранжированном (упорядоченном по величине) ряде (см. рис. 1). Затем каждому значению присваивается ранг от 1 до N, где N — количество анализируемых объектов (в нашем случае от Ф1 до Ф15). Так как несколько элементов в исследуемой выборке имеют один и тот же ранг, то каждому из них присваивается среднее значение (средний ранг). Совокупность элементов выборки, имеющих одинаковое значение, называют связкой, а количество одинаковых значений — ее размером. Поскольку в исследовании рассмотрены субъективные оценки объективных явлений, то есть экспертные оценки, а закон распределения изучаемых переменных не является нормальным, то одним из способов статистического анализа данной выборки является определение коэффициента корреляции Спирмена (табл. 2).
Коэффициент корреляции Спирмена вычисляется по формуле:
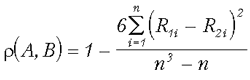 |
где R1i и R2i — ранги i-того объекта для каждой из сравниваемых переменных.
С учетом наличия совпадающих значений (связок) знаменатель уменьшается на величину:
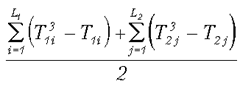 |
где L1 и L2 — количество связок в T1i и T2j — размеры связок (количество элементов в них).
Таблица 2
Ранговая корреляция (метод Спирмена)
|
Ф1 |
Ф2 |
Ф3 |
Ф4 |
Ф5 |
Ф6 |
Ф7 |
Ф8 |
Ф9 |
Ф10 |
Ф11 |
Ф12 |
Ф13 |
Ф14 |
Ф15 |
|
|
Ф1 |
1,0000 |
0,5159* |
0,2221 |
0,1094 |
0,0901 |
0,0396 |
0,0537 |
0,0197 |
0,2047 |
0,0927 |
0,0576 |
0,1217 |
0,1928 |
0,1110 |
0,1078 |
|
Ф2 |
0,5159** |
1,0000 |
0,2224 |
0,0867 |
0,1138 |
0,0363 |
0,0618 |
0,0403 |
0,1796 |
0,1013 |
0,0355 |
0,0491 |
0,1639 |
0,1253 |
0,2300 |
|
Ф3 |
0,2221 |
0,2224 |
1,0000 |
0,3451 |
0,4324 |
0,1698 |
0,0909 |
0,1275 |
0,1959 |
0,1527 |
0,0583 |
0,0945 |
0,1725 |
0,0391 |
0,1754 |
|
Ф4 |
0,1094 |
0,0867 |
0,3451 |
1,0000 |
0,1742 |
0,1452 |
0,2612 |
0,0865 |
0,1342 |
0,2126 |
0,1428 |
0,1905 |
0,0497 |
0,0766 |
0,1305 |
|
Ф5 |
0,0901 |
0,1138 |
0,4324 |
0,1742 |
1,0000 |
0,4346 |
0,1271 |
0,2187 |
0,0567 |
0,1832 |
0,1080 |
0,1233 |
0,0592 |
-0,0142 |
0,0932 |
|
Ф6 |
0,0396 |
0,0363 |
0,1698 |
0,1452 |
0,4346 |
1,0000 |
0,2302 |
0,2853 |
-0,0477 |
0,1314 |
0,0162 |
-0,0372 |
-0,0968 |
0,0176 |
0,0336 |
|
Ф7 |
0,0537 |
0,0618 |
0,0909 |
0,2612 |
0,1271 |
0,2302 |
1,0000 |
0,2649 |
0,1950 |
0,1686 |
0,1537 |
0,1325 |
0,0545 |
-0,0375 |
0,0994 |
|
Ф8 |
0,0197 |
0,0403 |
0,1275 |
0,0865 |
0,2187 |
0,2853 |
0,2649 |
1,0000 |
0,0538 |
0,1403 |
0,0672 |
-0,0255 |
-0,0086 |
0,0095 |
-0,0342 |
|
Ф9 |
0,2047 |
0,1796 |
0,1959 |
0,1342 |
0,0567 |
-0,0477 |
0,1950 |
0,0538 |
1,0000 |
0,3549 |
0,3442 |
0,3475 |
0,2471 |
0,0941 |
0,2185 |
|
Ф10 |
0,0927 |
0,1013 |
0,1527 |
0,2126 |
0,1832 |
0,1314 |
0,1686 |
0,1403 |
0,3549 |
1,0000 |
0,5527 |
0,4267 |
0,1762 |
0,0422 |
0,1667 |
|
Ф11 |
0,0576 |
0,0355 |
0,0583 |
0,1428 |
0,1080 |
0,0162 |
0,1537 |
0,0672 |
0,3442 |
0,5527 |
1,0000 |
0,6293 |
0,2726 |
0,0167 |
0,1509 |
|
Ф12 |
0,1217 |
0,0491 |
0,0945 |
0,1905 |
0,1233 |
-0,0372 |
0,1325 |
-0,0255 |
0,3475 |
0,4267 |
0,6293 |
1,0000 |
0,2711 |
0,0441 |
0,2273 |
|
Ф13 |
0,1928 |
0,1639 |
0,1725 |
0,0497 |
0,0592 |
-0,0968 |
0,0545 |
-0,0086 |
0,2471 |
0,1762 |
0,2726 |
0,2711 |
1,0000 |
0,2832 |
0,1334 |
|
Ф14 |
0,1110 |
0,1253 |
0,0391 |
0,0766 |
-0,0142 |
0,0176 |
-0,0375 |
0,0095 |
0,0941 |
0,0422 |
0,0167 |
0,0441 |
0,2832 |
1,0000 |
0,1619 |
|
Ф15 |
0,1078 |
0,2300 |
0,1754 |
0,1305 |
0,0932 |
0,0336 |
0,0994 |
-0,0342 |
0,2185 |
0,1667 |
0,1509 |
0,2273 |
0,1334 |
0,1619 |
1,0000 |
* Полужирным шрифтом выделены наиболее значимые корреляционные взаимосвязи между исследуемыми параметрами, влияющими на формирование мнения работника первого стола.
** В экспертном анализе использовались показатели со значением r > 0,25 (в таблице — курсив).
Определение значимости исследуемой выборки
Поскольку проводили анализ случайных величин, одной величины коэффициента корреляции для вывода недостаточно. Необходимо было проверить, значимо ли он отличается от нуля. Статистическую значимость корреляции исследуемых факторов проверяли с помощью критерия Стьюдента. Фактически проверяли гипотезу о равенстве коэффициента корреляции нулю. Для этого рассчитывали критериальное значение по формуле:
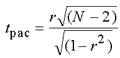 |
где r — значение коэффициента корреляции, а N — количество наблюдений.
Для подтверждения значимости коэффициента корреляции необходимо сравнить tрас и tтаб (табличное значение распределения Стьюдента обратное). Если расчетное значение t (tрас) больше табличного, взятого с N –2 степенями свободы, то нулевая гипотеза отвергается. Это означает, что коэффициент корреляции значимо отличается от нуля (с выбранным уровнем значимости). Результаты проведенного статистического сравнения (табл. 3) доказывают значимость корреляционной связи для каждого исследуемого фактора отдельно и в общем.
Таблица 3
Значимость коэффициентов корреляции (“+” значимо, “-” не значимо) при сравнении с tтаб =2,048 (правомерной для данной выборки)
|
? |
Ф1 |
Ф2 |
Ф3 |
Ф4 |
Ф5 |
Ф6 |
Ф7 |
Ф8 |
Ф9 |
Ф10 |
Ф11 |
Ф12 |
Ф13 |
Ф14 |
Ф15 |
|
Ф1 |
– |
+ |
+ |
+ |
– |
– |
– |
– |
+ |
– |
– |
+ |
+ |
+ |
+ |
|
Ф2 |
+ |
– |
+ |
– |
+ |
– |
– |
– |
+ |
+ |
– |
– |
+ |
+ |
+ |
|
Ф3 |
+ |
+ |
– |
+ |
+ |
+ |
– |
+ |
+ |
+ |
– |
– |
+ |
– |
+ |
|
Ф4 |
+ |
– |
+ |
– |
+ |
+ |
+ |
– |
+ |
+ |
+ |
+ |
– |
– |
+ |
|
Ф5 |
– |
+ |
+ |
+ |
– |
+ |
+ |
+ |
– |
+ |
+ |
+ |
– |
– |
– |
|
Ф6 |
– |
– |
+ |
+ |
+ |
– |
+ |
+ |
– |
+ |
– |
– |
– |
– |
– |
|
Ф7 |
– |
– |
– |
+ |
+ |
+ |
– |
+ |
+ |
+ |
+ |
+ |
– |
– |
– |
|
Ф8 |
– |
– |
+ |
– |
+ |
+ |
+ |
– |
– |
+ |
– |
– |
– |
– |
– |
|
Ф9 |
+ |
+ |
+ |
+ |
– |
– |
+ |
– |
– |
+ |
+ |
+ |
+ |
– |
+ |
|
Ф10 |
– |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
– |
+ |
+ |
+ |
– |
+ |
|
Ф11 |
– |
– |
– |
+ |
+ |
– |
+ |
– |
+ |
+ |
– |
+ |
+ |
– |
+ |
|
Ф12 |
+ |
– |
– |
+ |
+ |
– |
+ |
– |
+ |
+ |
+ |
– |
+ |
– |
+ |
|
Ф13 |
+ |
+ |
+ |
– |
– |
– |
– |
– |
+ |
+ |
+ |
+ |
– |
+ |
+ |
|
Ф14 |
+ |
+ |
– |
– |
– |
– |
– |
– |
– |
– |
– |
– |
+ |
– |
+ |
|
Ф15 |
+ |
+ |
+ |
+ |
– |
– |
– |
– |
+ |
+ |
+ |
+ |
+ |
+ |
– |
Результаты данного статистического анализа выборки (498 аптек-респондентов в 25 региональных центрах Украины), составившей по отношению к генеральной совокупности до 20 тыс. фармацевтов и провизоров первого стола, свидетельствуют (с достоверностью до 95%), что выборка репрезентативна генеральной совокупности и достаточно отражает структуру генеральной совокупности (по данным Госкомстата, в Украине на 2001 г. число фармацевтов и провизоров составило около 35 тыс. человек). Другими словами, влияние выбранных для исследования факторов и их взаимосвязи, позволяет с бoльшей достоверностью оценить (экспертная оценка), за счет каких моментов формируется мнение фармацевта/провизора в его рекомендации потребителю того или иного препарата.
Коментарі
Коментарі до цього матеріалу відсутні. Прокоментуйте першим